단백질과 단어 접기
AI 기술은 ChatGPT와 같은 대화형 언어 모델 외에도 다양한 분야에서 발전 중입니다. 생명과학 분야에서 게임 체인저가 되어온 것은 바로 구글 DeepMind에서 개발한 단백질 구조 예측 AI인 AlphaFold입니다.
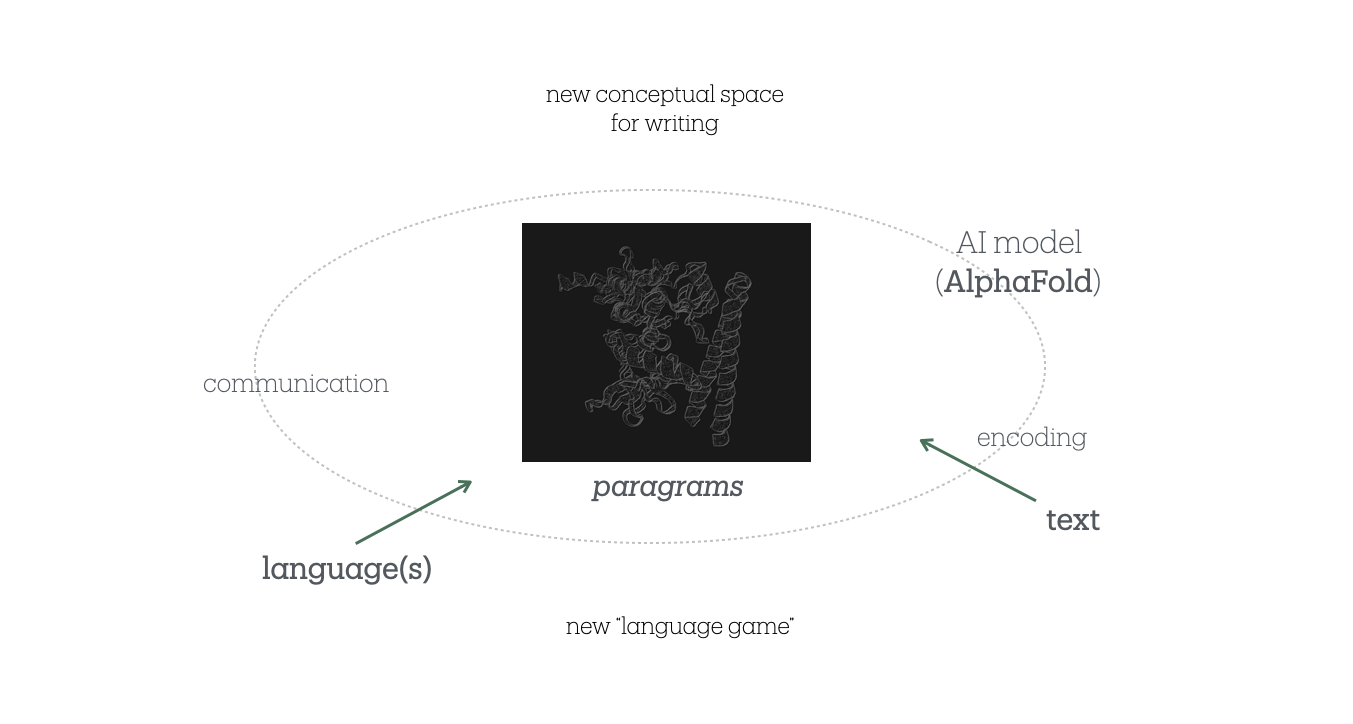
AlphaFold가 ‘언어놀이’의 맥락에서 흥미로운 이유는 단백질을 마치 언어처럼 다룬다는 점입니다. 아미노산 서열을 읽어내어 3차원 구조로 접는 과정은, 문자들이 공간에 배열되며 의미를 형성하는 것과 유사합니다. 이러한 접기의 원리를 문학적 실험으로 확장하여, AlphaFold를 통해 단백질과 자연어 단어를 접는 ‘구체시’를 창작해보겠습니다.
배경: 단백질과 자연어
단백질과 우리가 쓰는 언어는 여러 모로 비슷한 구조를 가지고 있습니다. 단백질은 20종류의 아미노산이라는 기본 단위로 이루어져 있고, 각 아미노산은 G, A, V, L 같은 한 글자로 표현됩니다. 이 아미노산들이 길게 연결되어 사슬을 만들고, 그 사슬이 2차, 3차, 4차 구조로 접히면서 단백질 고유의 기능이 생깁니다. 이러한 단순한 원리를 바탕으로 셀 수 없이 많은 종류의 단백질이 존재합니다.
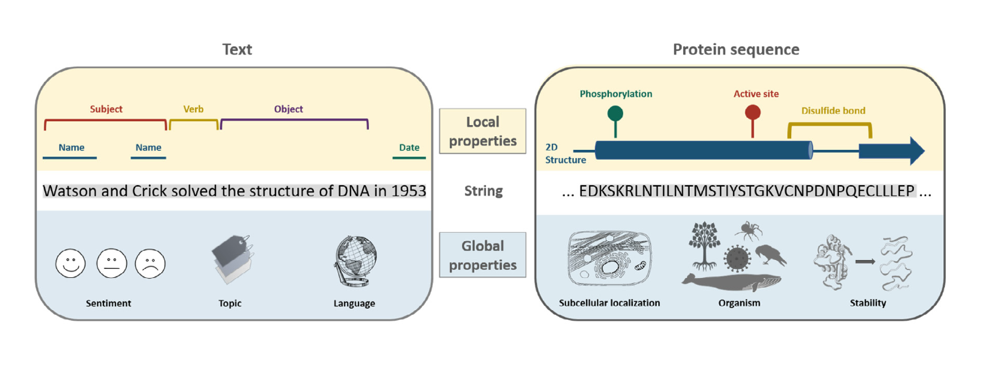
Image Source: Ofer, D., Brandes, N., & Linial, M. (2021). The language of proteins: NLP, machine learning & protein sequences. Computational and Structural Biotechnology Journal, 19, 1750-1758.
마찬가지로 언어도 제한된 숫자의 알파벳과 같은 기본 단위가 있고, 이 글자들이 순서대로 배열되면서 단어와 문장을 만들어냅니다. 단백질과 자연어 시스템 모두 작은 단위들의 조합으로 거의 무한한 가능성을 만들어낼 수 있다는 점에서 같습니다. 또한 둘 다 순서가 중요합니다. 단백질은 N-말단에서 C-말단 방향으로 읽히고, 문장은 왼쪽에서 오른쪽으로 읽힙니다. 언어가 다양한 물질적·상징적 영역을 가로질러 암호화되고 변환될 수 있는 열린 과정이라는 점에서 무척 흥미로운 사실입니다.
이러한 구조적 유사성에 기반해 AlphaFold에서 임의의 자연어 단어를 다른 단백질과 함께 접히게끔 만드는 실험을 할 수 있습니다. 이는 물론 AlphaFold의 원래 목적과 거리가 먼 '목적 외적(para-functional)' 사용입니다. ‘재전유’라고 표현할 수도 있습니다. 특히 AI 모델을 단순한 예측 도구가 아닌 새로운 개념적 쓰기(conceptual writing)의 공간으로 재구성하는데 목적이 있습니다.
disclaimer 1: 어떤 과학자들에게는 AlphaFold의 본래 목적에서 벗어난 이 개념예술적 실험이 오독되거나 불편하게 받아들여질 수 있습니다. 이 작업은 과학적 또는 공학적 성취를 목표로 한 것이 아님을 밝힙니다.
S대의 한 과학자는 예술 관련 행사에서 발표한 이 작업에 대해 논리적으로 “맞지 않다”라고 지적했습니다. 드물지만, 분야 간 관점 차이에서 비롯된 반응으로 보입니다. 그는 단백질 접힘의 과학적 원리 등을 설명하며, 이 작업이 개념적으로 “레벨이 맞지 않다”고 주장했습니다. 물론 과학의 관점에서는 그렇게 보는 것이 자연스럽습니다. 다만 이 작업은 과학적 탐구를 목표로 하지 않습니다. 저 역시 과학고등학교와 공대 환경에서 20년 가까이 몸담으며 과학적 사고를 훈련받은 바 있지만, 이 작업은 다른 목적과 접근을 가지고 있음을 소개하였습니다. 그러나 세션 체어였던 그는 작업의 전제나 목표에 대해 함께 검토하기보다는, 두서없이 과학적/공학적 기준으로만 평가하는 방향으로 대화를 진행했습니다. 이러한 사례는 예술에 대한 관심이나 이해의 차이로 넘길 수도 있겠습니다. 그러나 이 과학자가 세계적인 예술 행사의 진행 위원이었다는 점을 고려하면, 학제간 대화에 필요한 상호 존중과 이해의 방식에 대해 재고할 필요가 있는 것 같습니다.
disclaimer 2: AlphaFold 개발진의 노벨상 수상과 이 작업의 동기는 무관함을 밝힙니다.
이 작업은 AlphaFold라는 기술 자체를 옹호하거나 비판하는 등의 정치적 동기와 무관하게 진행되었습니다. 이미 2024년 초 AlphaFold Server를 통해 작업이 시작되었고, 같은 해 10월 데미스 하사비스를 포함한 관련 연구자들이 노벨 화학상을 수상했습니다.
2. 단백질과 단어 접기
(1) 단백질 고르기
첫 번째 실험은 간단한 단어 패턴을 특정 단백질의 결합력을 통해 접는 것이었습니다. 하지만 무작위의 문자 서열을 3차원 구조로 접는 것은 생각보다 어렵습니다. 그러한 서열은 대부분 단백질도 그 무엇도 되지 못하기에, 홀로 접히기도 힘들고, 다른 단백질과 같이 접히기도 힘들죠.
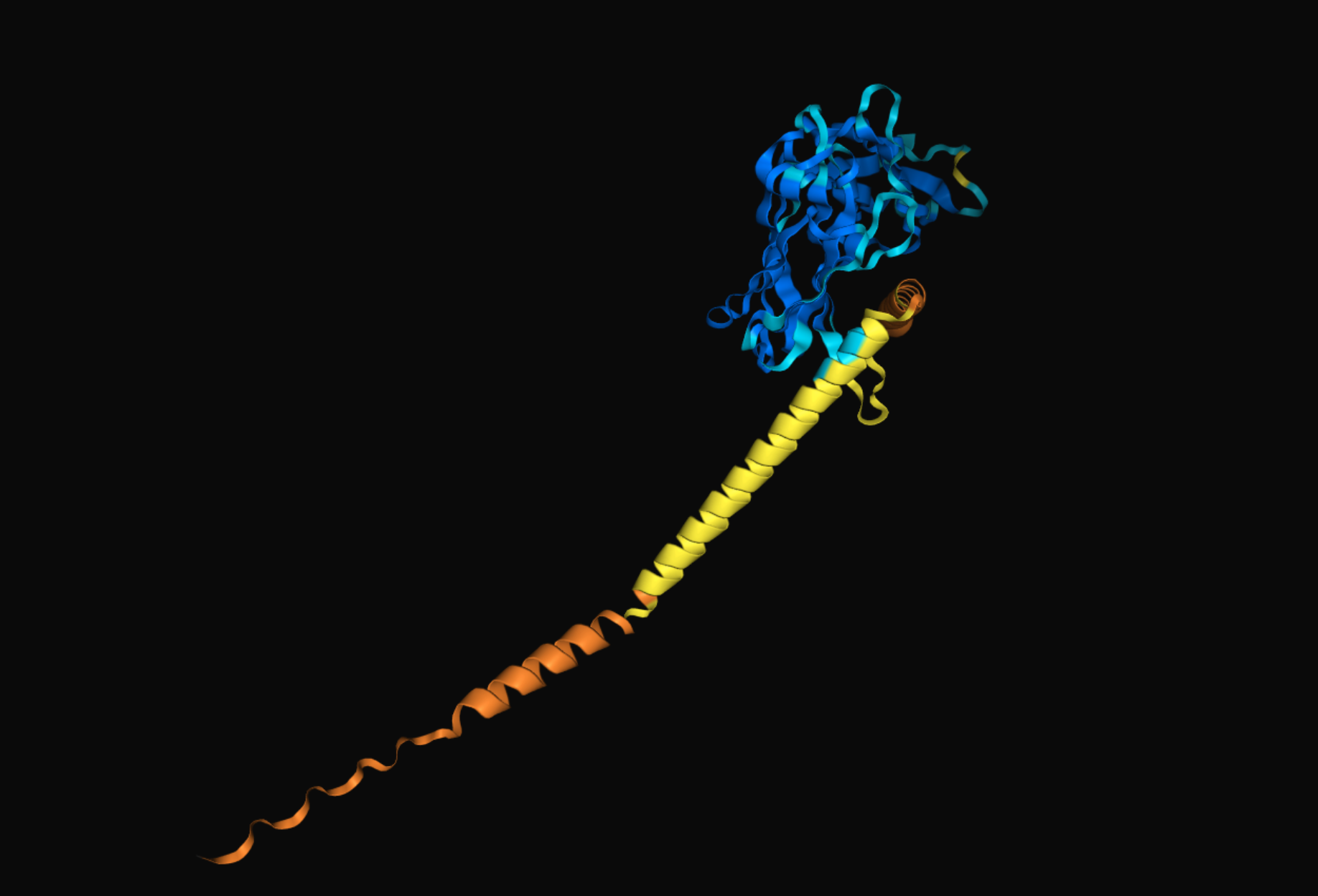
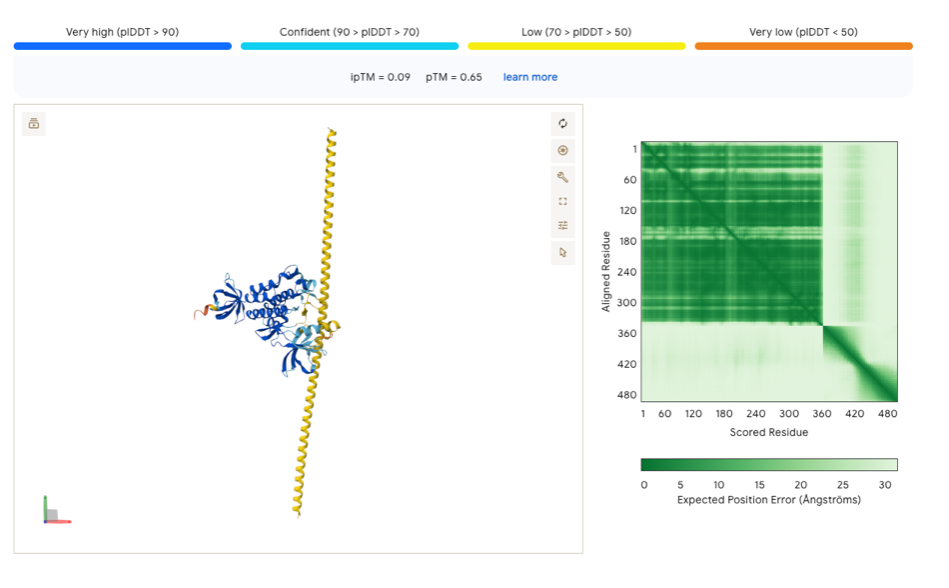
보통은 아래 이미지의 노란 코일과 같이 곧게 펴진 형태로 나타납니다. 더 정확히 표현하면, 그렇게 “나타난다”라기보다는 AlphaFold가 해당 서열에 대한 유의미한 접힘 구조를 찾을 수 없는 것이라고 볼 수 있습니다.
노란 코일 옆에 놓인 것은 실제로 존재하는 한 단백질의 모습입니다. 둘 사이의 상호작용은 없는 상태입니다.

아래 왼쪽 이미지와 같이 미세한 접힘이 생기기도 합니다.
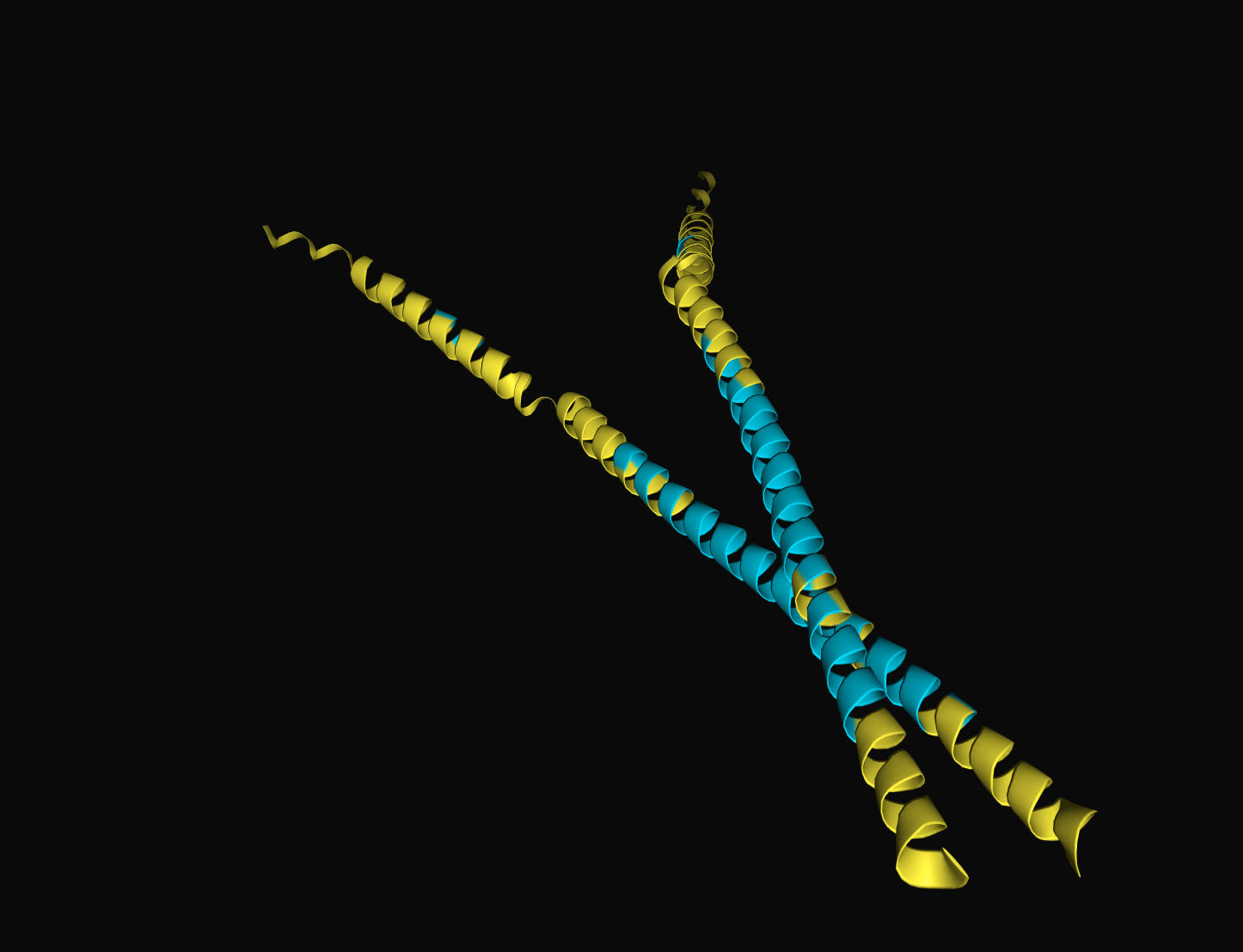
아예 자연어 서열끼리 접어보면 주로 오른쪽 이미지와 같은 지루한 상황이 연출됩니다.
따라서 실험을 진행하기 위해서는 먼저 수천 수만 개의 단백질 후보 중에서 대체 어떠한 종류의 단백질이 비교적 높은 상호작용성을 가지는지 조사해야 했습니다. 이른바 ‘허브 단백질’(hub proteins)류와 ‘IDPs’(intrinsically disordered proteins)들이 유망한 후보군으로 떠올랐습니다. 이 단백질들은 높은 유연성을 가지고 있어 다양한 세포 환경에서 여러 파트너와 상호작용할 수 있습니다. 인공 설계된 '드 노보 단백질(de novo proteins)' 역시 좋은 후보로 꼽혔습니다. 명확히 정의된 결합 인터페이스와 다수의 표면 노출 소수성 패치(hydrophobic patch)를 가지고 있기 때문입니다.
대표적인 허브 단백질인 “p53”

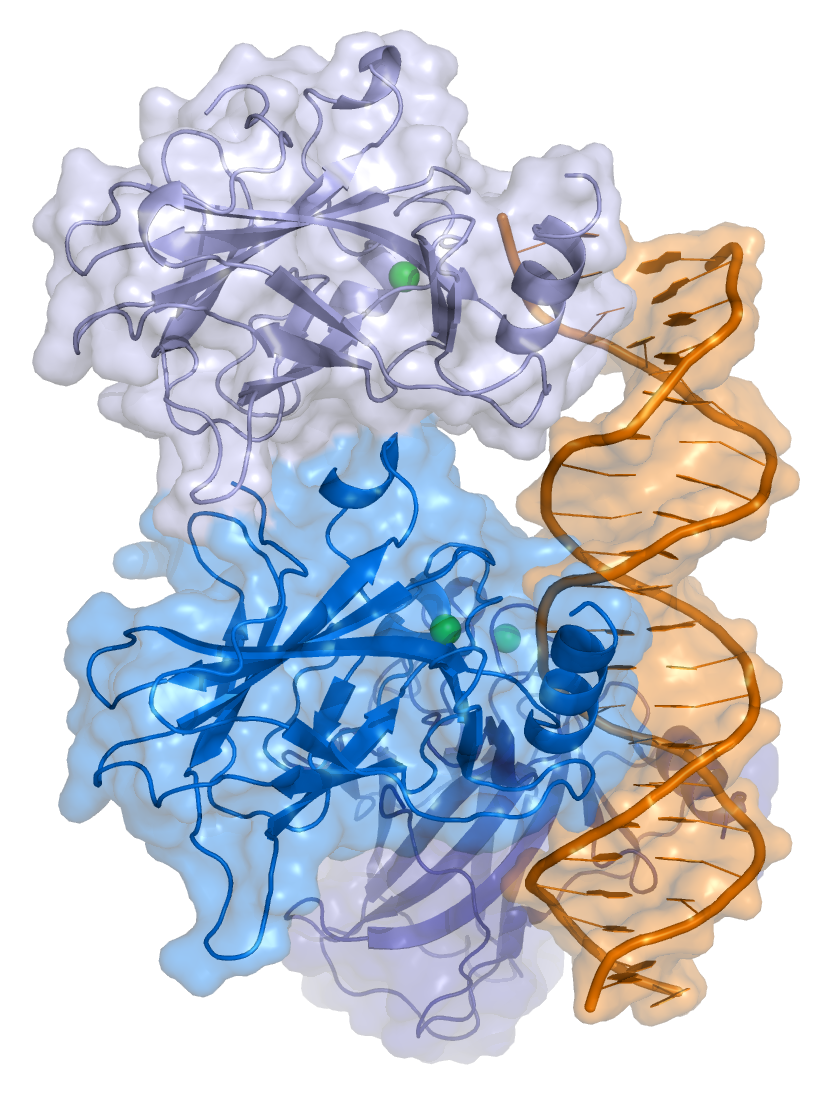
그렇게 RCSB Protein Data Bank에서 수많은 단백질을 탐색하는 시간을 가졌습니다. 결국 비교적 단순한 구조를 가진 ACK1 단백질인 “4HZS”를 잠정 파트너로 정했습니다. 이 단백질은 341개의 아미노산 서열(GSQSLTCLIGE ... TSVAGLSAQD)로 이루어져 있는데, 세포 신호 전달에서 다양한 역할을 하는 인산화 효소입니다.
GSQSLTCLIGEKDLRLLEKLGDGSFGVVRRGEWDAPSGKTVSVAVKCLKPDVLSQPEAMDDFIREVNAMHSLDHRNLIRLYGVVLTPPMKMVTELAPLGSLLDRLRKHQGHFLLGTLSRYAVQVAEGMGYLESKRFIHRDLAARNLLLATRDLVKIGDFGLMRALPQNDDHYVMQEHRKVPFAWCAPESLKTRTFSHASDTWMFGVTLWEMFTYGQEPWIGLNGSQILHKIDKEGERLPRPEDCPQDIYNVMVQCWAHKPEDRPTFVALRDFLLEAQPTDMRALQDFEEPDKLHIQMNDVITVIEGRAENYWWRGQNTRTLCVGPFPRNVVTSVAGLSAQD(2) 접기 테스트
이제 4HZS의 결합 파트너로 어떤 자연어 단어를 접을지 고민했습니다. 상징적으로 ‘playful’한 실험을 구상해보고자 했습니다. 그래서 단백질과 함께 접을 대상을, 어떠한 재료(금속, 점토 등)나 사물(진주, 나뭇잎 등)의 특성을 묘사하는 합성어(형용사+명사)로 설정했습니다. 이를테면 아래와 같은 단어들입니다.
WHITEPEARL
HARDMETAL
DARKVELVET
REDCLAY
GREENLEAF
PALEASH
참고로 아미노산은 표준적으로는 20개 종류만을 사용하기 때문에, 이 기준으로는 알파벳 표기 중 B, J, O, U, X, Z가 사용되지 않습니다. 제가 만든 합성어에도 B, J, O, U, X, Z가 포함되지 않도록 했습니다.
물론 원하는 결과가 처음부터 잘 나오지는 않았습니다. 아래는 4HZS와 “HARDMETAL chain”(단어 “HARDMETAL”을 여러 번 반복하여 서열로 입력한 것)을 접어본 결과입니다. 노란 코일 가닥으로 허공에 떠 있습니다(접힘 없음).
이제 AlphaFold Server에 들어가 접힙 예측 실험을 했습니다. AlphaFold Server에서는 누구나 무료로 단백질 서열을 입력하고 접힘 예측을 해볼 수 있습니다. (https://alphafoldserver.com/, 당시 AlphaFold2 기반, 현재는 AlphaFold3)
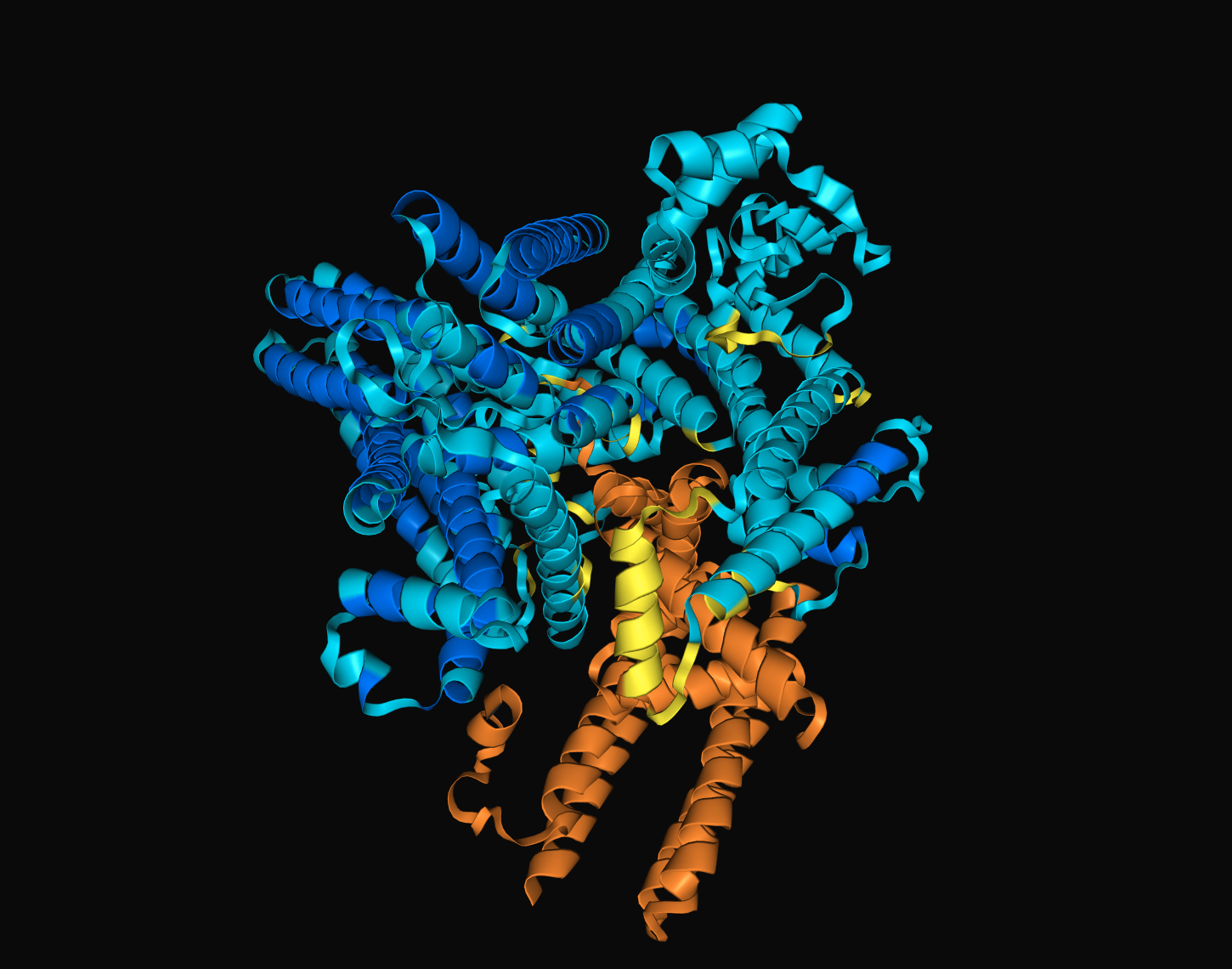
아래는 파트너 단백질을 바꾸어 “8C7L”이라는 p21 단백질을 “WETCLAY”와 접어본 결과입니다. 이미지 아래 “Sequence”를 자세히 보면 “WETCLAY”를 14번 반복한 98개 글자(아미노산)로 이루어진 문자열이라는 것을 알 수 있습니다. 노란 코일이 주황으로 변하고, 살짝 굽어졌습니다. 파란 구조물로 표현된 “8C7L”은 본래 무언가를 감싸거나 수용할 수 있는 역량이 큰 단백질 같아 보입니다.
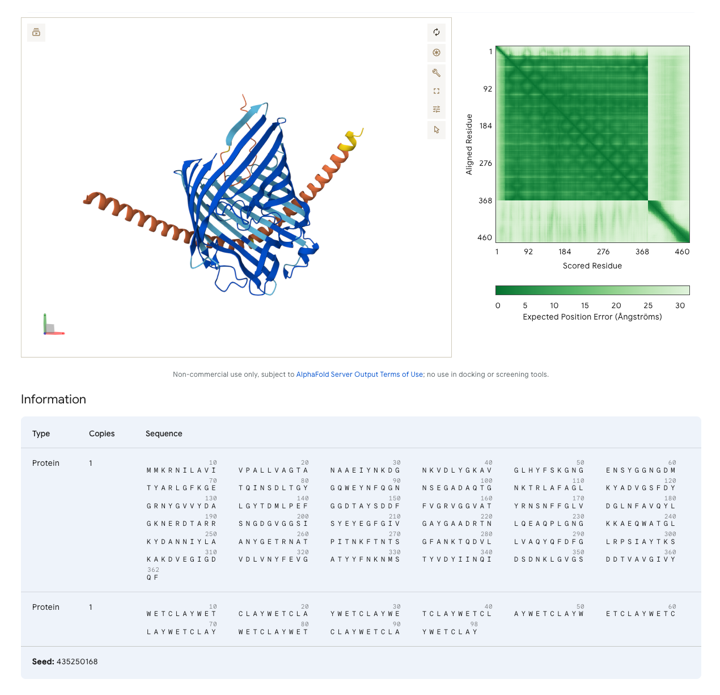
다양한 조합을 시도하며 흥미로운 구조들을 관찰할 수 있었습니다.

(3) 구체시 쓰기
*이 작업은 2025년 5월 27일 서울에서 개최된 the 30th ISEA (International Symposium on Electronic/Emerging Art), Academic Conference에서 발표한 것입니다. 자세한 내용: An, Mihye. 2025. Concrete writing with proteins. Proceedings of 30th International Symposium on Electronic/Emerging Art (ISEA2025), 260-267.
cf. 구체시(concrete poetry)란?
구체시는 1950년대 서구에서 등장한 시적 운동입니다. 구체시는 시를 '읽는 대상'이 아닌 '지각하는 대상'으로 만들고자 했습니다. 전통적인 시가 언어를 개인의 감정이나 생각을 표현하는 도구로 사용했다면, 구체시는 언어 자체의 물질성에 주목합니다. 글자와 단어를 기하학적 패턴이나 시각적 형태로 배열하여, 시의 구조 자체가 의미의 일부가 되도록 만듭니다.
구체시의 선구자인 스위스의 오이겐 곰링거(Eugen Gomringer)는 "구체시는 무언가에 대한 시가 아니라, 그 자체로 하나의 실재"라고 말했습니다. 그러니까 구체시인들은 시를 개인의 주관적 감정 표현에서 해방시키고, 그대신 언어를 하나의 '사물' 또는 '유용한 물건'(commodity)으로 제시하고자 했습니다. 우리가 잘 아는 말라르메나 E. E. 커밍스도 구체시의 선구자였다고 볼 수 있습니다.
구체시는 시각 시, 소리 시, 움직이는 시 등 다양한 형태로 발전하면서 언어의 다차원성을 탐구했습니다. 문자를 그림처럼 배치하거나, 타이포그래피를 활용하거나, 숫자나 기호를 사용하기도 했습니다. 이들은 언어가 의미를 전달하는 수동적 매체가 아니라, 그 자체로 생성적이고 능동적인 과정임을 보여주고자 한 것입니다. 20세기 구체시의 이러한 유산은 디지털 환경에서 지속적으로 확장되어 왔습니다.
*구체시에 관해서는 단백질을 동반하지 않는 다른 언어놀이에서 더 자세히 다룰 계획입니다.

다양한 테스트를 바탕으로 우선 간단한 두 개의 구체시를 구성했습니다. 그리고 그것들을 "paragram"이라 이름 붙였습니다. 'para-'(옆에, 나란히)와 'gram'(쓰인 것, 글자)을 결합한 이 용어는 단백질 언어와 자연어가 나란히 배치되어 접히면서 생성되는 새로운 형태의 ‘쓰기’를 의미합니다.

A paragram of 4HZS and REDCLAY10
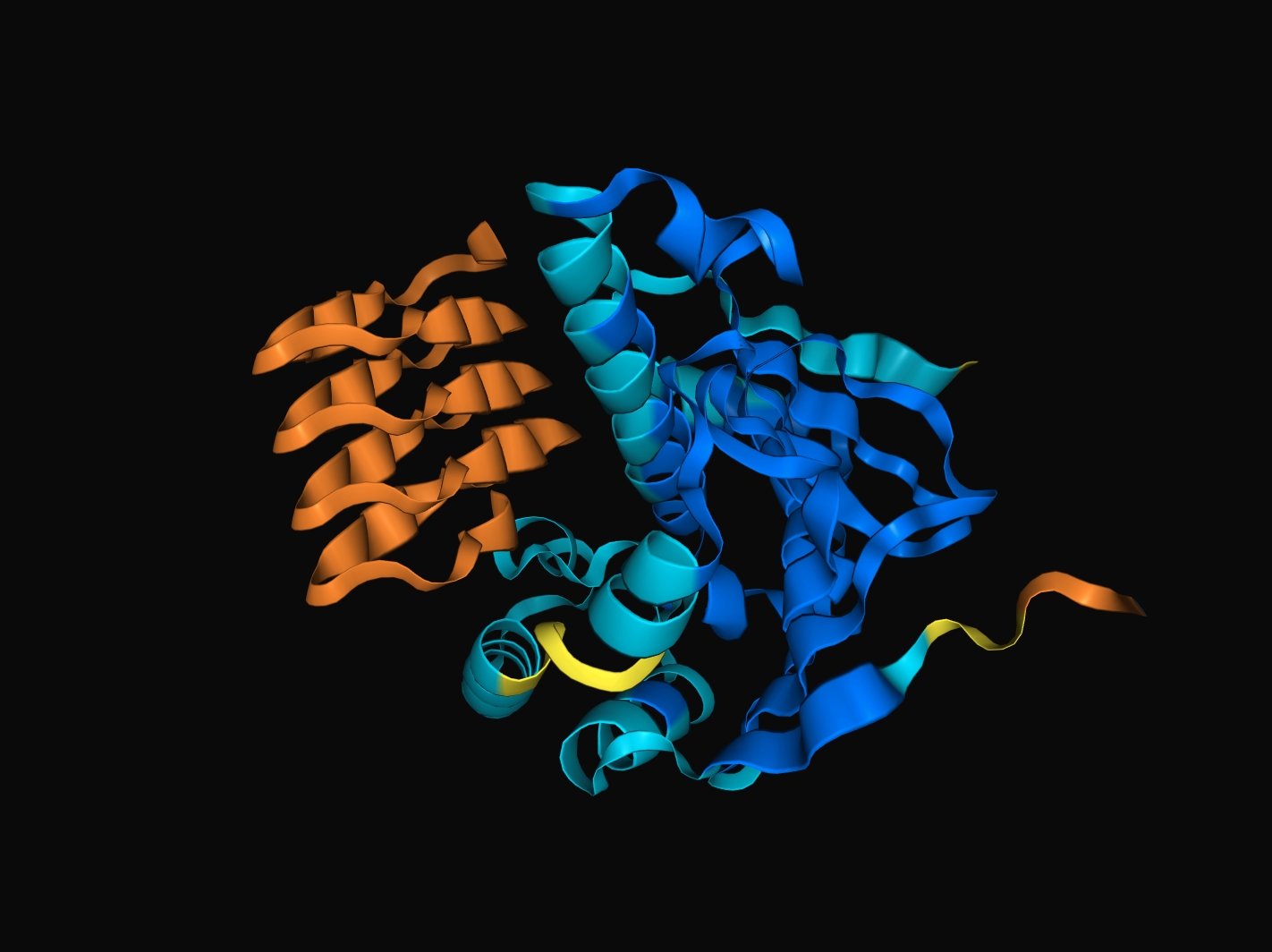
첫 번째 paragram은 “REDCLAY10"과 4HZS를 접었을 때 가장 높은 확률로 나타나는 결과입니다. 여기서 "REDCLAY10"은 "REDCLAY"의 알파벳 서열이 10번 반복되어 총 70개의 서열이 된 것을 말합니다. 흥미로운 점은, 더 긴 서열을 가진 REDCLAY20이나 REDCLAY30은 4HZS와 전혀 상호작용하지 못했다는 점입니다. 그러나 REDCLAY10(붉은 점토 10)의 골격은 중심선을 따라 단정히 접혔습니다.
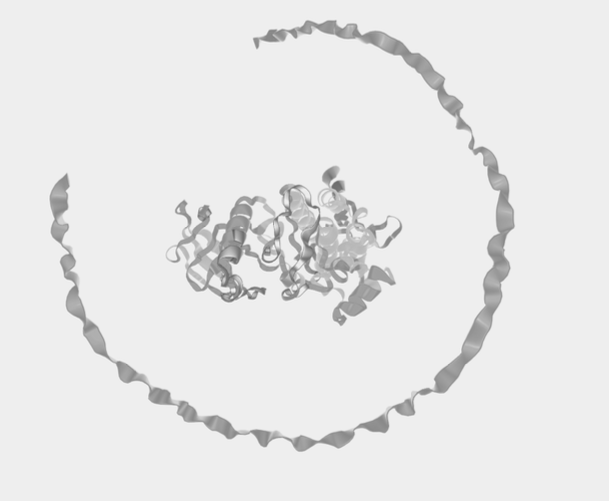
A paragram of 4HZS and CHEAPGLASS10
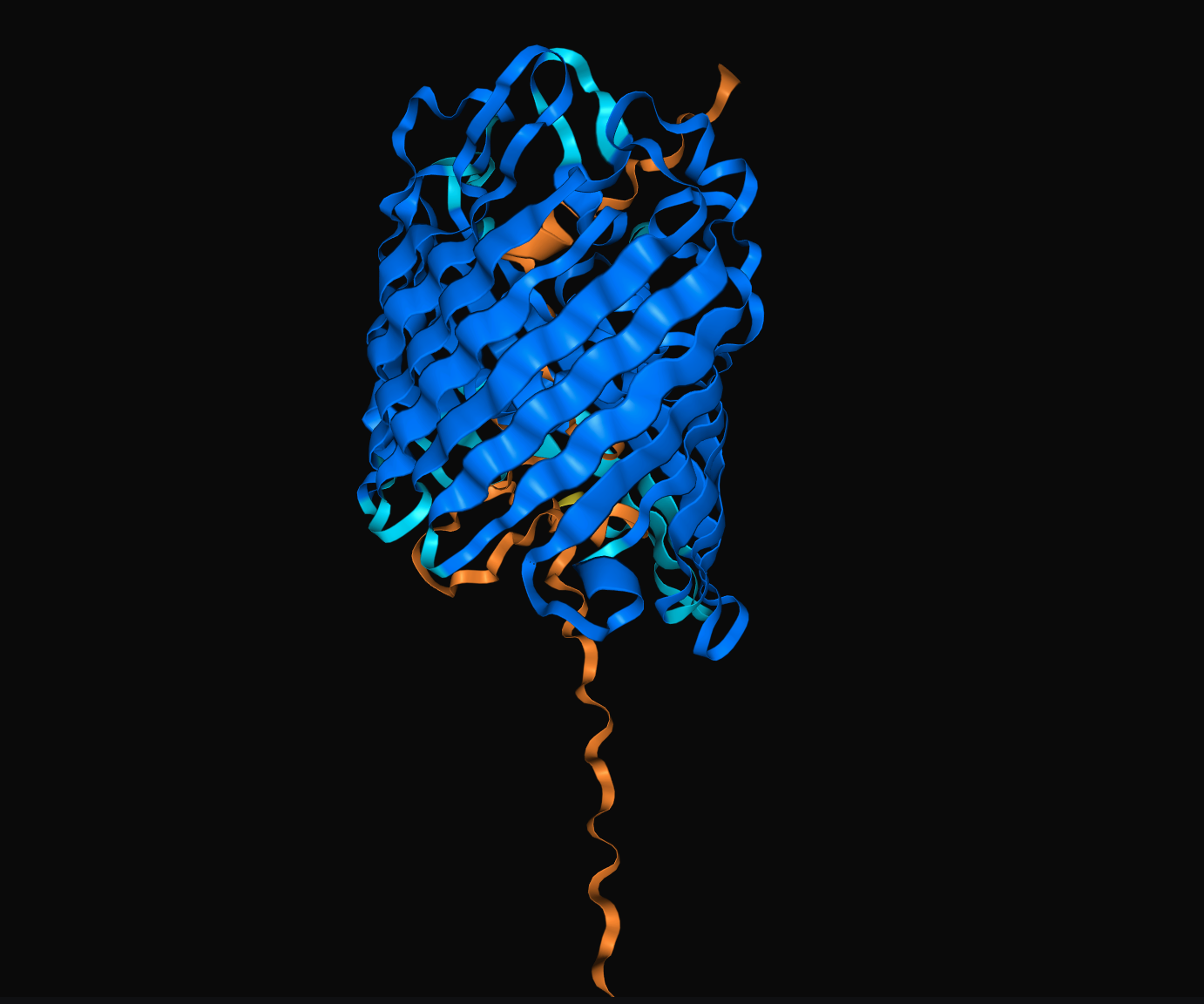
두 번째 paragram은 "CHEAPGLASS10"과 4HZS를 접었을 때 나타난 모습입니다. CHEAPGLASS(값싼 유리)가 단백질 주위를 원형으로 휘돌며 띠를 이룹니다.